
I keep thinking about better ways to improve my method for pseudo-3D hand-drawn graphics in games. It isn’t a very advanced method, and yet expands older methods that have been abandoned decades ago, creating traditional animation in 3D games in ways that computer animation has still be unable to mimic.
The problem with it? Never mind how it looks (I am not a professional animator in any sense, that it looks as good as it does with my ability alone is enough to convince me of its potential). It takes a lot of work to animate (still less than the typical animated film, which is hardly a comparison). More importantly, it takes a lot of RAM and hard drive space. Unlike CGI models, where the animation takes less data than the model itself (and thus animations can be added to a model with less concern), my method multiplies RAM used with every frame of animation. Every frame is its own, hand-drawn texture.
Add that there are different perspectives of one character (currently 24 in my latest version). If I have one animation with five frames, that’s 24*5 = 120 frames. If I have several animations, or add more frames for smoother animation, you can see how one character can have thousands of hand-drawn frames.
What’s more, I purposely separate my character into parts (body, legs, arms, face, etc.) in hopes that I can combine animations from each part, reducing redundant animation and saving frames. This makes sense, but nothing I’ve made requires that many unique animations for it to be practical. This is when one Twitterer (shout out to @Jeckdev) suggested making parts of the body smaller.
You see, I separate parts of the body, but all parts take up a frame of the same size (at full resolution, if I have five parts, then I have five 1024x1024px frames). A lot of empty space is taken there, but if I shrunk the parts not taking as much space, it would take less memory. The figures below show this:
Method 1
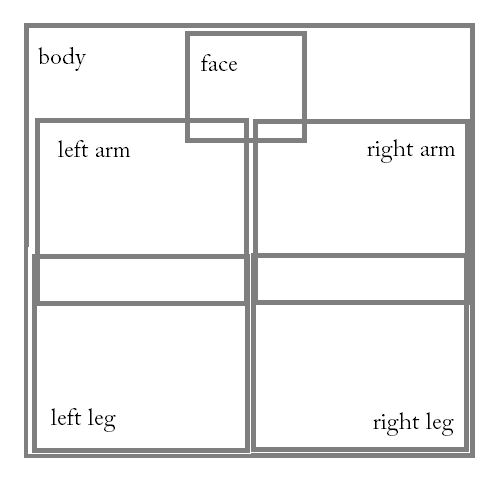
Method 2
This method is only effective if I use square textures with powers of 2 (256×256, 512×512, 1024×1024, etc.) in the Unity3D game engine. But let’s do the math based on the above: 6 x 1024×1024 = about 6 million pixels for method 1. But the new method (number 2) might use 1024×1024 + 4 x (512×512) + 256×256 = 1 million + 1 million + 65,000 = about 2 million pixels. That’s about 1/3 the amount of RAM I’m using now. That’s great news for adding more animation or unique characters in the same scene. This is only effective for characters with a lot of empty white-space in their textures, of course.
So on the good side, RAM and hard drive space is reduced significantly. Also, shadows and shading could have more variety if the parts are separated and scaled differently like this.
But what’s the drawback? This also means less flexibility for the “artist.” For this to work, I need to manually place objects in the right position for (about 24) perspectives of a character. If the artists wants to change the character, it could cause a lot of strife to update the character’s body positions. And this assumes the character is in roughly the same pose throughout: do you want the character to lay on the ground and get up? Do you want one arm to reach over to the other side? Good luck. You’d have to somehow control position and animate the parts themselves, not just what texture is on it at the time (similar to what Ubisoft’s “Ubiart” framework does, I suppose). It’s possible, but makes a already-messy system even more complex. Whereas Method 1, while expensive, allows the utmost level of freedom for whatever needs to be made, not unlike original methods of traditional animation.
And what if I wasn’t using layers at all? Or rather, if I simplified the layers down to three for method 1? I would be using about 3 million pixels vs 2 million, still not as well as Method 2. I would also have less flexibility to separate the animations. But for characters with little animation to begin with, it suffices. Of course, I could go even further and only use one layer for the best use of resources, but then the mild depth effect is lost.
This shows there is a lot that can be added to improve this visual method and make it more sophisticated. A developer could make good money just developing a system to do the above stuff easily. But for now, I’ll stick with reducing the amount of layers to begin with (I think 3 is enough), and target a 4 GB RAM system minimum, and keep this post in mind if I keep getting resource trouble. But it’s good to know that there are ways to cut my RAM by half without loss of quality. If anyone else has any other ideas, please let me know!